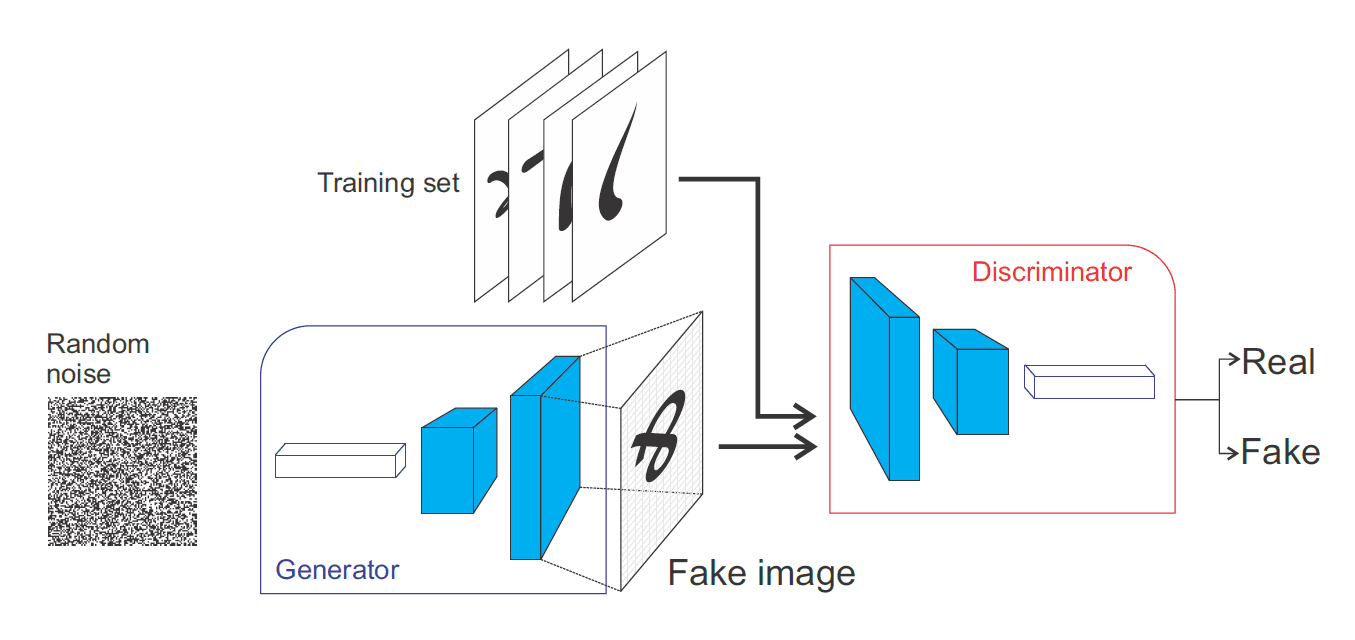
Evaluation of GANs model -Part 2
Computer Engineer Sudent with deep Interest in data science.
Let's learn more about the feature extraction that we discussed in part - I.
In the last article, we discussed why evaluating GANs model is hard and what are the ways to evaluate it. We concluded that it's better to use the feature distance method rather than the pixel distance method.
What is feature distance?
It is a method of using features extracted from the classifier to differentiate between real and fake images.
Classifier -> Features -> Differentiate between real and fake.
We extract the features of images using a pre-trained classifier. The fully connected layers are used for the classification and the CNN part is used for feature extraction. So, why not only use it and eliminate fully connected layers? The max-pooling layers give the features.
It is experimental to know which pooling layers to use because you never know which pooling layer gives the best-needed features.
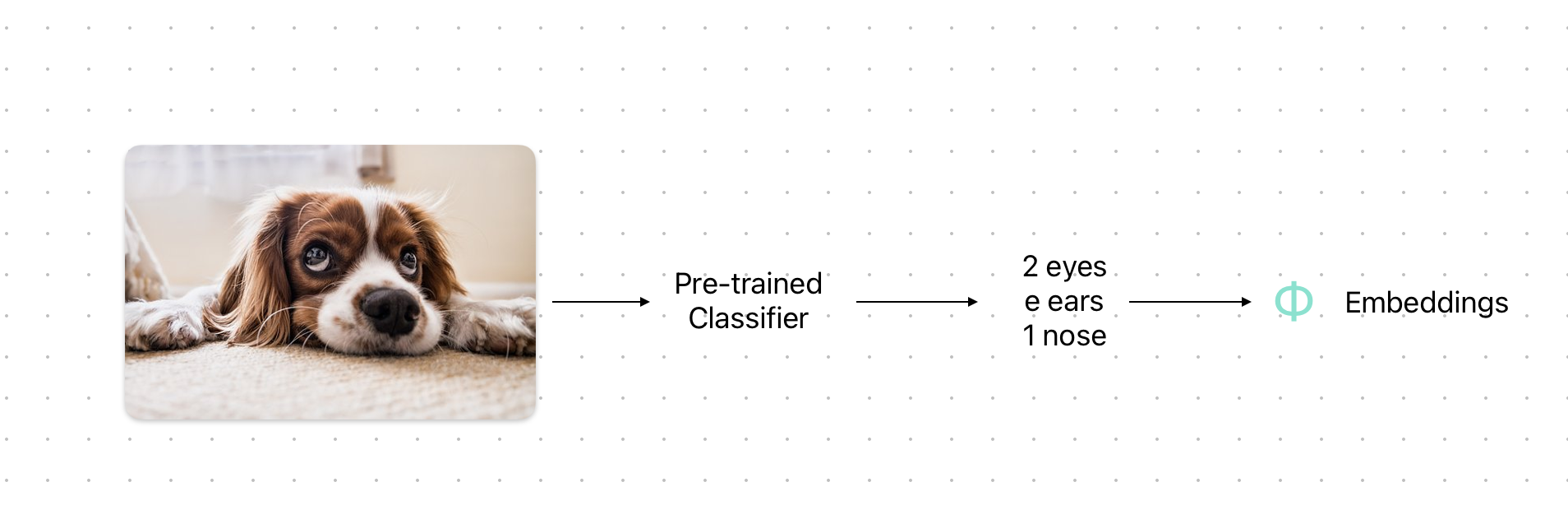
The features are called embeddings as the features are condensed to smaller numbers.
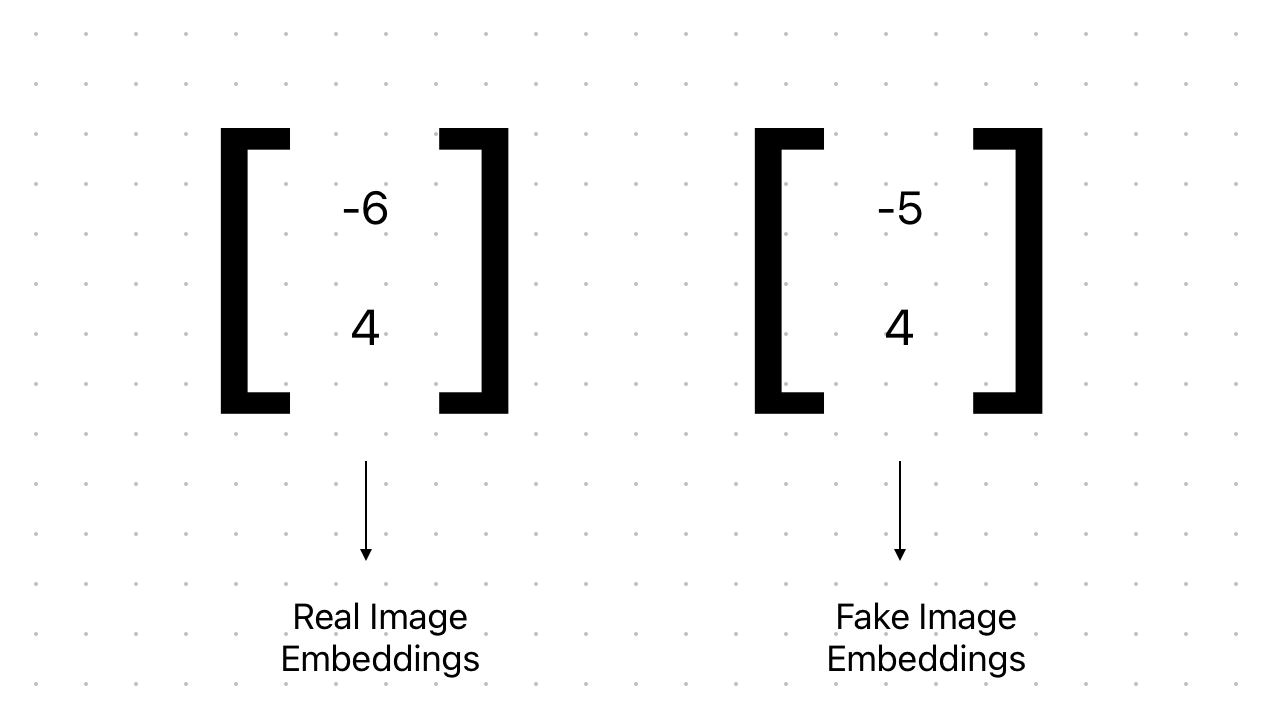
Since the real and fake image embeddings are closer, so we can say, the generator is doing well.
How to compare embeddings?
Frechet Inception Distance (FID)
It can be used to calculate the distance between curves and distributions.
$$d(x,y) = (uX, -uY)^2 + (\sigma X - \sigma Y)^2$$
The mean gives you a sense of the centre and the standard deviation gives how far apart are the distribution.
Multivariate Normal Distributions
It is the normal distribution over large dimensions.
so, we use covariance as it measures the variance between two distributions.
so, for multivariate normal distribution, we use the following formula.
$$FID = ||uX - uY||^2 + Tr(\sum X + \sum Y - 2 \sqrt{ \sum X \sum y} )$$
Where:
Tr = Trace of a matrix (sum of diagonal)
Real and fake embeddings are two multivariate normal distributions.
Then we can compare real and fake with the FID formula.
X = Real
Y = Fake
$$uX = Mean. of. Real$$
$$ uY = Mean.of.fake$$
$$ \sum X = Covariance.of.Real.embeddings$$
$$ \sum Y = Covariance .of.Fake.Embeddings$$
The lower the FID, the closer the distributions, the better.
Shortcomings of FID
Use pre-trained inception-v3 moel which may not capture all features
Needs a large sample size
Limited statistics used (Mean and standard deviation)
Slow to run.
There is another method known as inception score which can be used to compare the features. (Readers are advised to study it by themselves, The math too vague to include in this blog.)
Sampling and Truncation
Sampling is an important technique. When you use random noise of mean zero and standard deviation of one, you get better quality results but they look like normal images with less variation. However, when you use another random noise you get more diverse images but of less quality. so, there is always a trade-off.
We can conclude that the evaluation of GANs model is very much sample dependent rather than model parameters, so choose wisely how you sample.
So, to reduce the trade-off between diversity and fidelity we can use the truncation technique.
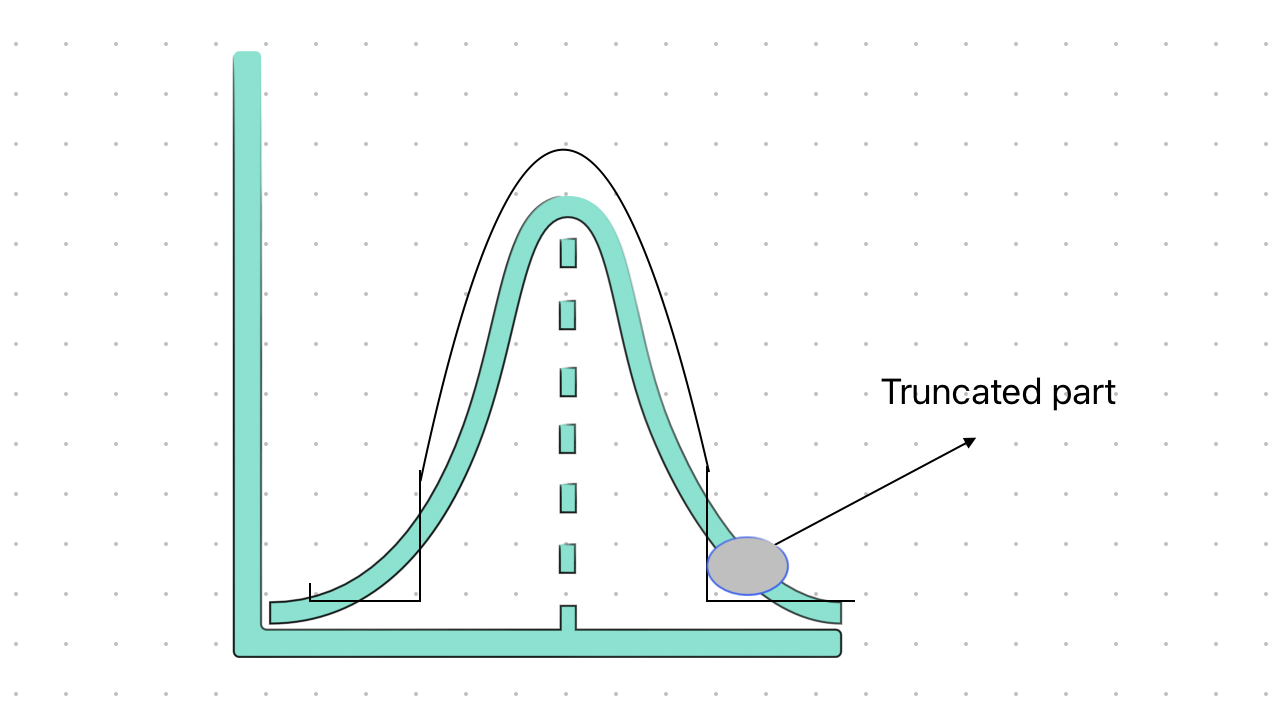
Fig: Truncation of the sample.



