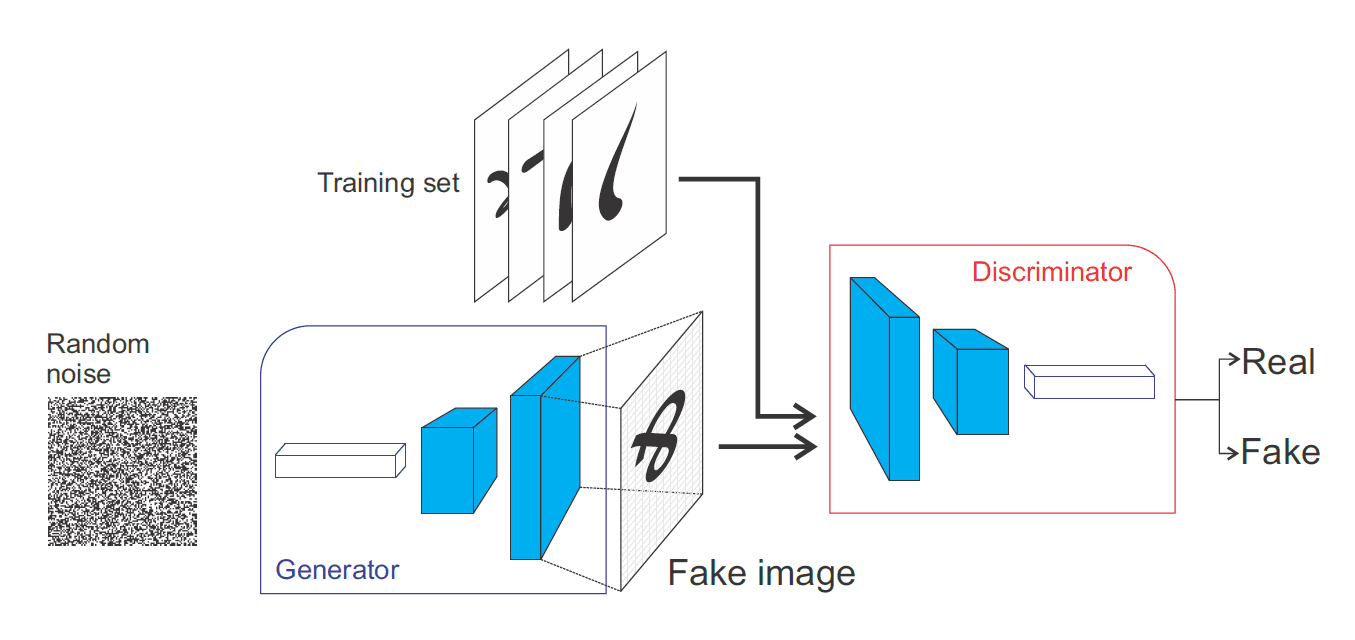
Devanagari handwriting and letters Generation with Deep Convolution Generative Adversarial Network (DCGAN)
Learn the basis of GAN.

Computer Engineer Sudent with deep Interest in data science.
Hello Everyone,
The following two images are generated by Deep Convolution Generative Adversarial Network trained over Devanagari Numbers and Letters.
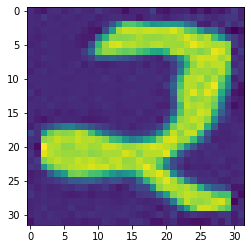

Fig: generated images
The dataset was taken from GitHub (https://github.com/kcnishan/Nepali_handwritten_digits_recognition) and the framework used to design this GAN was PyTorch.
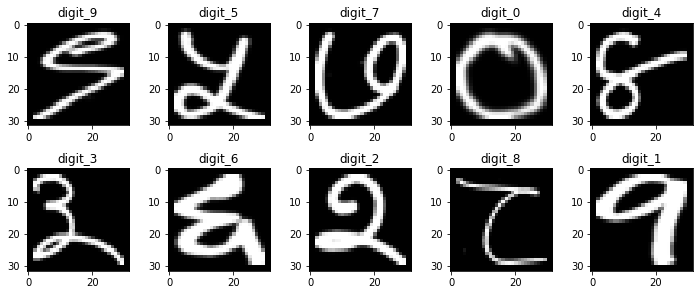

Fig: Original Dataset
Then, the image path and its label are converted to dataframe using the following script.
img_path = []
label = []
for each in os.listdir(train_path):
for x in os.listdir(train_path+'/'+each):
img_path.append(train_path+'/'+each+'/'+x)
label.append(each)
img_path_test = []
label_test = []
for each in os.listdir(Test_path):
for x in os.listdir(Test_path+'/'+each):
img_path_test.append(Test_path+'/'+each+'/'+x)
label_test.append(each)
df = pd.DataFrame(list(zip(img_path, label)), columns=['path', 'label'])
df_test = pd.DataFrame(list(zip(img_path_test, label_test)), columns=['path', 'label'])
LbE = LabelEncoder()
df.label = LbE.fit_transform(df.label)
df_test.label = LbE.fit_transform(df_test.label)
Then a custom dataset loader was designed which returns tensor values of images and target label. The label was not used for GAN but later was useful for prediction.
class LetterDataset(Dataset):
def __init__(self, df):
self.fpath = df.path
self.label = df.label
self.transform = T.Compose(
[T.ToPILImage(),
T.ToTensor(),
T.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
),
T.Grayscale(num_output_channels=1)
]
)
def __len__(self):
return len(self.fpath)
def __getitem__(self, ix):
img = self.fpath[ix]
target = self.label[ix]
img = cv2.imread(img)
im = self.transform(img)
return torch.tensor(im/255).to(device).float(), torch.tensor(target).long().to(device)
BCELoss is used as the loss algorithm and Adam as the optimiser. As per the beta, the optimiser parameters such as beta1, and beta2 values are taken as 0.5,0.999 and the learning rate as 0.0002. The models are trained at 50 epochs.
image_size = 32
batch_size = 32
z_dim =100
beta1 = 0.5
lr=0.0002
epochs = 50
sample_size=8
The initial size of images is 32 * 32 and no changes are done with the image height and width but all images are normalised to ( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225] )
(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
The basis GAN architecture is:
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
self.model = nn.Sequential(
nn.ConvTranspose2d(100,64*8,4,1,0,bias=False,),
nn.BatchNorm2d(64*8),
nn.ReLU(True),
nn.ConvTranspose2d(64*8,64*4,4,2,1,bias=False),
nn.BatchNorm2d(64*4),
nn.ReLU(True),
nn.ConvTranspose2d( 64*4,64*2,4,2,1,bias=False),
nn.BatchNorm2d(64*2),
nn.ReLU(True),
nn.ConvTranspose2d(64*2,1,4,2,1,bias=False),
nn.Tanh()
)
self.apply(weights_init)
def forward(self,input): return self.model(input)
class Discriminator(nn.Module):
def __init__(self ):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
#input size=32*32
nn.Conv2d(1, 64, kernel_size=4, stride=2, padding=1),
#16*16
nn.LeakyReLU(0.2),
disc_layer(64, 64*2, 4,2,1), #8x8
disc_layer(64*2, 64*4, 4,2,1),#4x4
nn.Conv2d(64*4, 1, kernel_size=4,stride=2,padding=0),#1x1
nn.Sigmoid()
)
self.apply(weights_init)
def forward(self, input):
return self.disc(input)
The training script for both Generator and Discriminator is:
def train_disc(optimizer,real_data, fake_data):
optimizer.zero_grad()
prediction_real = disc(real_data)
error_real = loss_fn(prediction_real.squeeze(), \\
torch.ones(len(real_data)).to(device))
error_real.backward()
prediction_fake = disc(fake_data)
error_fake = loss_fn(prediction_fake.squeeze(), \\
torch.zeros(len(fake_data)).to(device))
error_fake.backward()
optimizer.step()
return error_real + error_fake
def train_gen(optimizer,fake_data):
optimizer.zero_grad()
prediction = disc(fake_data)
error = loss_fn(prediction.squeeze(), \\
torch.ones(len(fake_data)).to(device))
error.backward()
optimizer.step()
return error
for i in range(50):
loss_g = 0.0
loss_d = 0.0
print(f'Epoch: _________*****{i}*****_______')
for ix, batch in tqdm.tqdm(enumerate((trn_ldr))):
x, y = batch
x = x.to(device)
b_size = len(x)
data_fake = gen(create_noise(b_size, z_dim)).detach()
data_real = x
loss_d +=train_disc(optimizer_d, data_real, data_fake)
data_fake = gen(create_noise(b_size, z_dim))
loss_g += train_gen(optimizer_g,data_fake)
generated_image = gen(noise).cpu().detach()
plt.imshow(generated_image[0].reshape(32,32))
plt.show()
print(loss_g, loss_d)
epoch_loss_g = (loss_g / ix)
epoch_loss_d = loss_d / ix
losses_g.append(epoch_loss_g)
losses_d.append(epoch_loss_d)
print(f'Epoch: _________*****{i} Generator Training Loss : {epoch_loss_g} *****_______')
print(f'Epoch: _________*****{i} Discriminator Training Loss : {epoch_loss_d} *****_______')
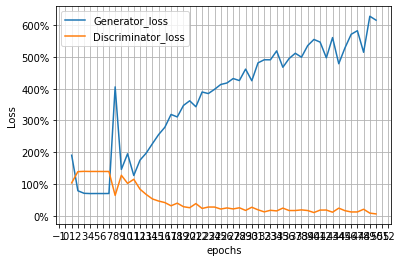
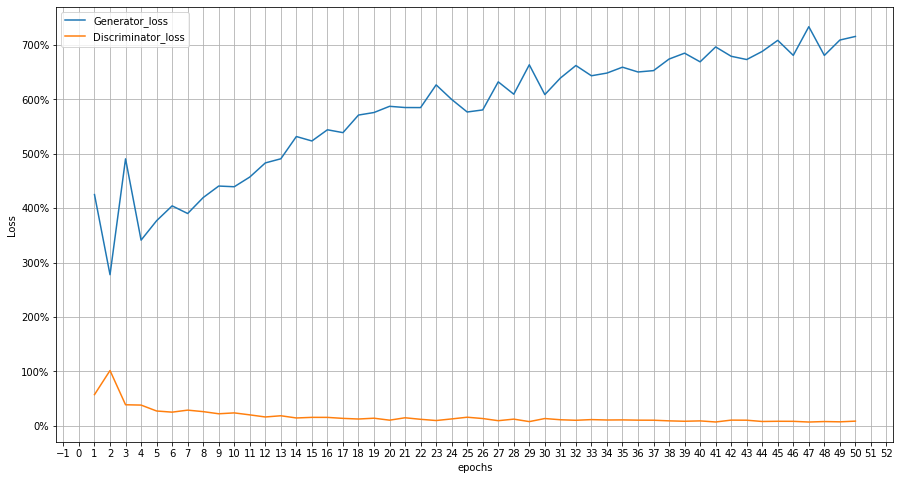
Along with generation, I have also made a CNN model which predicts the letters and consonants. The accuracy is set as a metric to determine the model worthiness and CrossEntropyLoss is the loss metric.
def conv_layer(ni, no, kernel_size, max_pool_num=2, stride=1,):
return nn.Sequential(
nn.Conv2d(ni, no, kernel_size, stride),
nn.BatchNorm2d(no),
nn.LeakyReLU(0.2),
nn.MaxPool2d(max_pool_num)
)
from torch.nn.modules.activation import Softmax
def get_model():
model = nn.Sequential(
conv_layer(1,8,2),
conv_layer(8,16, 2),
conv_layer(16, 64, 2),
nn.Flatten(),
nn.Linear(64*3*3,192),
nn.ReLU(),
nn.Linear(192, 64),
nn.ReLU(),
nn.Linear(64, 36),
nn.Softmax()
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
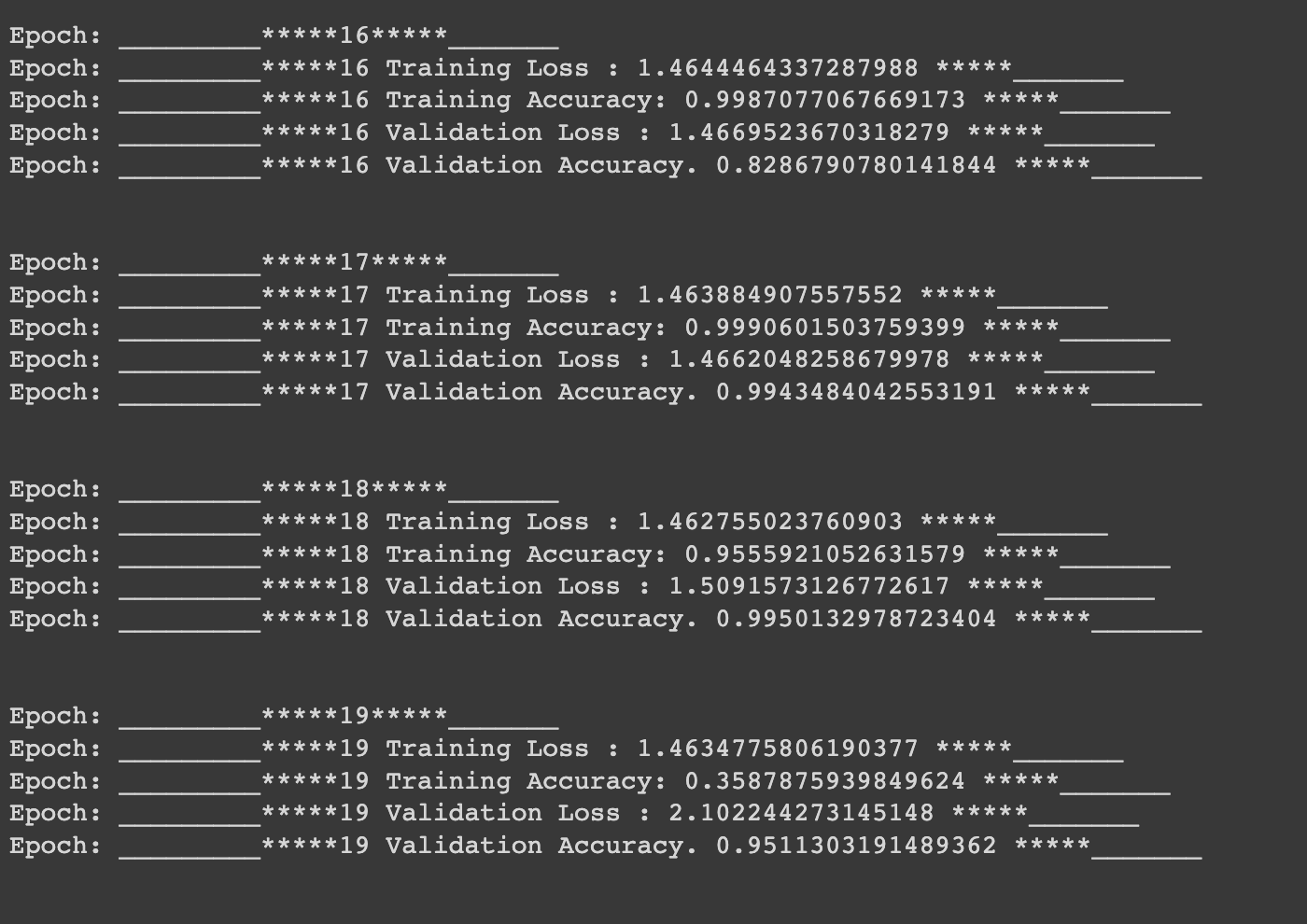
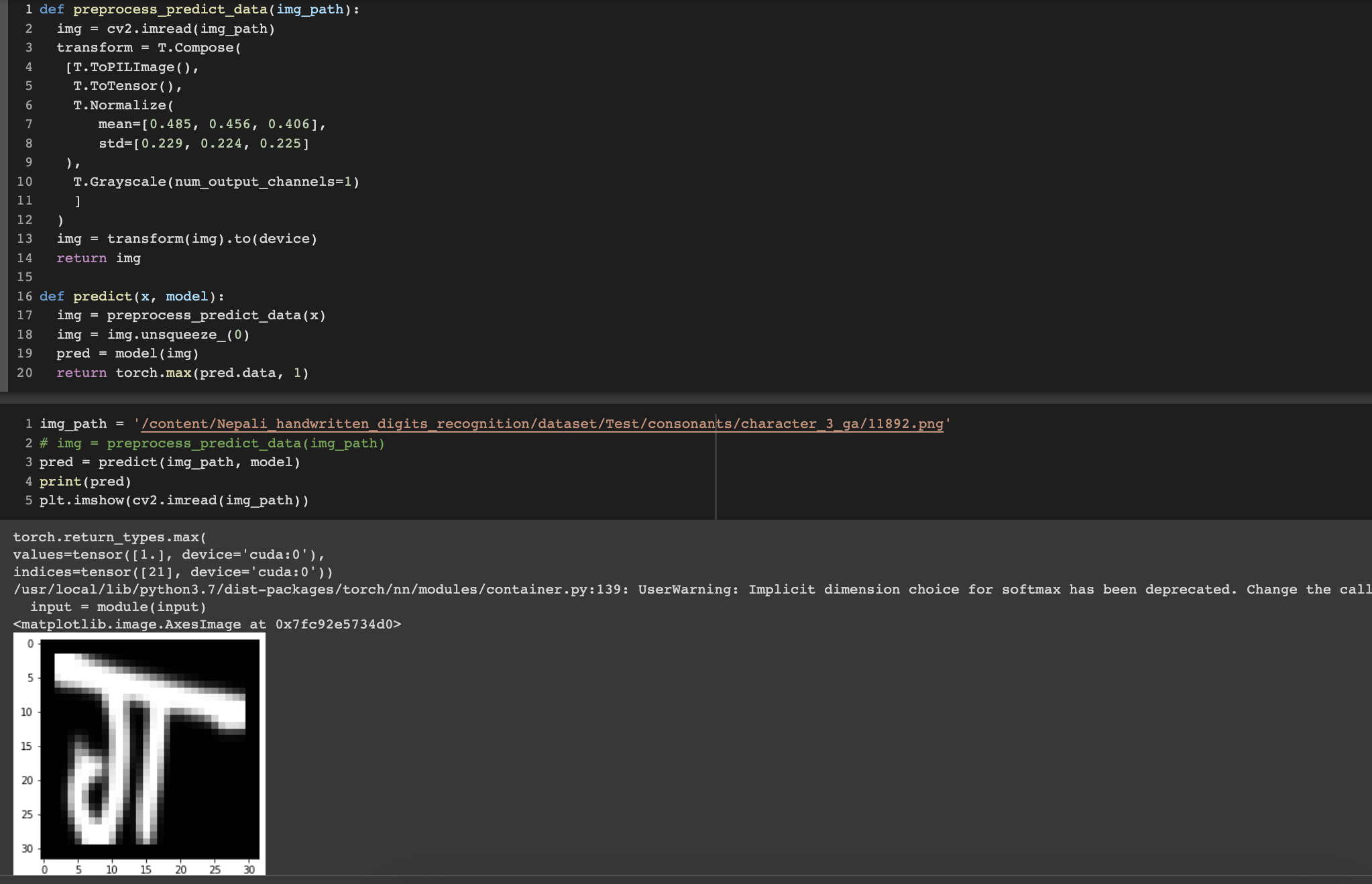
One Fun Fact:
In the dataset, there was a problem, a folder was inside the image folder, which was not usual and manual looking at all datasets was not possible. So, I made a script to check the faulty folder and removed it. Took a little time to do but in the end, it was an interesting task to do. After all, when you have the power of python, it becomes easy.
import os
from os import listdir
from PIL import Image
count= 0
for each in os.listdir(Test_path):
for x in os.listdir(Test_path+'/'+each):
if x.endswith('.png'):
try:
img = Image.open(Test_path+'/'+each+'/'+x)
img.verify()
except:
print(each+'/'+x)
else:
print(each+'/'+x)
Future works:
→ Go for transfer learning in the prediction model.
→ Build better Discriminator and Generator models.
→ Try conditional GAN
→ Build an interface where people can generate images as well as classify that generated images.
The repository for the full project is:
https://github.com/bibekebib/Nepali-Letters-and-Numbers-classification-generation